
OpenStack
OpenStack cloud for your home lab
This is going to be a series of blog posts about running OpenStack for a home lab. It’s not for everyone, but I’ve found it very useful.
OpenStack is a great set of microservices that can be run and provide a set of cloud interfaces into your home lab. I use a Linux desktop for everything and prefer using libvirt/virt-manager for most virtual machines (VM). But at some point, it’s very useful to have a VM server where you can run a script and get a virtual network with VMs. It’s also really nice to have Ansible and other tools with cloud interfaces such that you can play with it locally and still be compatible with major clouds when you want to run things there.
OpenStack is run by a large number of massive companies for their internal IT as well as some public clouds like OVH. While it’s designed for these use cases, it’s quite possible to run some of these microservices locally on a single machine. The easiest approach is running the pre-built DevStack inside a VM. At some point, if this is enticing, running these service with customization is going to be very helpful.
General tips for running OpenStack at home
There’s a few things I’ve learned over years of running OpenStack that have a pretty big impact if you want to run it locally.
-
If you want to use block storage, all of the officially supported drivers are for big and expensive network storage systems. It’s not difficult to use a local ZFS driver and it makes running VMs in your home lab a lot nicer. I’ve got a driver I’ve kept updated and is in my GitLab. This is based on an older ZFS cinder driver but with various updates.
-
If you use Ubuntu or another distribution that has OpenStack, it’s likely an official release - and does not have updates. It’s not uncommon for there to be a problem that is fixed in a minor update. You can only get those updates when you sign up for the OpenStack support that costs money. Or, you can run OpenStack from the official opensource PyPi code and get all of the updates. If you don’t want to pay money, this is the best approach. There are official methods of deploying OpenStack, like ‘Charmed OpenStack’, but I’ve found it not flexible enough for a single machine installation.
-
When you make a VM in OpenStack, it gets a reservation on a compute host. What that means is, even if you don’t have all of your VMs running, they have CPU and Memory allocations. If you hit a limit, you can ‘shelve’ your VM which removes that reservation while letting you ‘unshelve’ and use the VM later. This can also be used to move a VM from one compute host to another.
-
A minimal set of microservices will take around 6GB to 8GB of memory. If using ZFS, you also need to allocate some maximum ARC memory for that. This memory overhead should be considered when deciding if you want to run OpenStack in your home lab.
OpenStack docker containers
I run OpenStack from a series of Docker containers. At some point, I plan to open source my configuration. However, it’s current state is likely to cause more trouble for others to use given many of the modifications I’ve made.
These are the containers I’m currently using for my hacking OpenStack server. It should give a decent idea how much memory is needed for the OpenStack microservices. Note that there is no load and this is a few minutes after bringing the containers up.
|
|
Adding up all of the memory usage brings me to 5,139MiB - that does not include the 8GB ZFS ARC max limit I’ve set. I generally allocate about 16GB memory for my underlying VM server. I will discuss these services in future blog posts, but for a summary, I’m running:
- Neutron - Virtual networking using openvswitch
- Nova - The VM compute service (thing actually running the qemu processes)
- Cinder - Block storage, and in my case using ZFS locally
- Horizon - Web UI that I don’t normally use. But can be quicker to open a local console into a VM using this.
- Memcached - In memory cache, which may end up going away
- DB - Persistent configuration for the OpenStack setup using MariaDB
- Glance - VM image service (upload an image and use it as a template for new VMs)
- RabbitMQ - Messaging between all of these microservices
- Keystone - Authentication and authorization
- Placement - Used to match a Nova compute host with the needs of a new VM
- DNS - Absolutely required to have DNS resolution (I’m using Bind9)
There’s a great many other OpenStack microservices to provide different specialized features, like direct container managment.
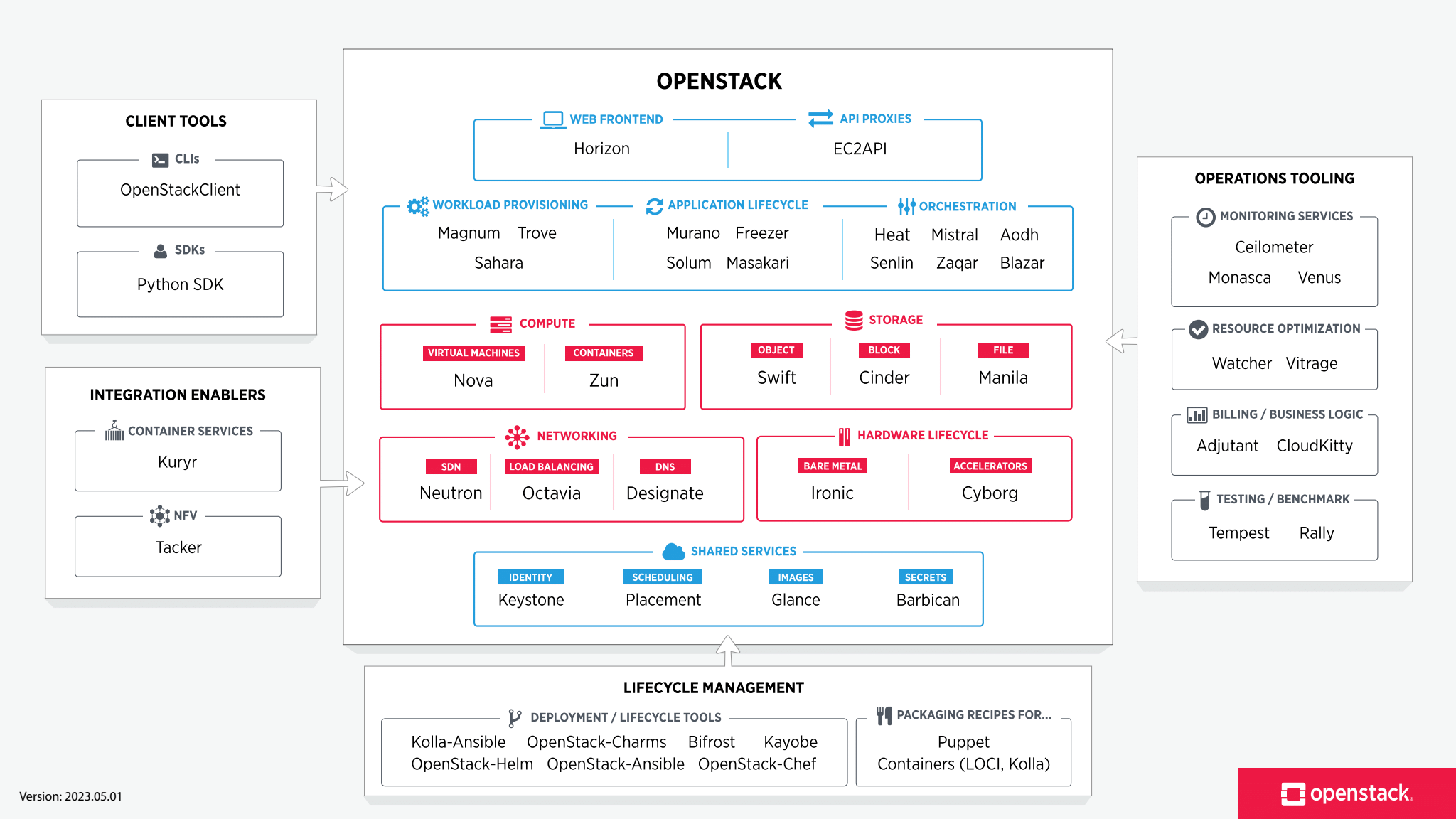
Overview of the OpenStack microservices
Comments
You can use your Fediverse (i.e. Mastodon, among many others) account to reply to this post.